Расширенный код Unix - Extended Unix Code
Расширенный код Unix (EUC) является многобайтовым кодировка символов система, используемая в основном для Японский, Корейский, и упрощенный китайский.
Структура EUC основана на ISO-2022 стандарт, который определяет способ представления наборов символов, содержащих максимум 94 символа, или 8836 (942) символов или 830584 (943) символов, как последовательности 7-битных кодов. Формы EUC могут быть только в наборах символов, совместимых с ISO-2022. С помощью схемы EUC можно представить до четырех наборов кодированных символов (называемых G0, G1, G2 и G3 или кодовых наборов 0, 1, 2 и 3).
G0 почти всегда ISO-646 совместимый набор кодированных символов, например US-ASCII, ISO 646: KR (KS X 1003) или же ISO 646: JP (нижняя половина JIS X 0201), который вызывается в GL (т.е. с очищенным старшим битом). Исключением из US-ASCII является то, что 0x5C (обратная косая черта в US-ASCII) часто используется для обозначения Знак иены в EUC-JP (см. ниже) и выиграл знак в EUC-KR.
Чтобы получить форму EUC для символа ISO-2022, старший бит каждого 7-битного байта оригинала ISO 2022 коды устанавливаются (добавлением 128 к каждому из этих исходных 7-битных кодов); это позволяет программному обеспечению легко различать, есть ли конкретный байт в строка символов принадлежит коду ISO-646 или коду ISO-2022 (EUC).
Наиболее часто используемые коды EUC: кодировки переменной ширины с символом, принадлежащим G0 (совместимый с ISO-646 набором кодированных символов), принимающим один байт, и символом, принадлежащим G1 (принимаемым набором кодированных символов 94x94), представленным в двух байтах. В EUC-CN форма ГБ 2312 и EUC-KR являются примерами таких двухбайтовых кодов EUC. EUC-JP включает символы, представленные до трех байтов, тогда как один символ в EUC-TW может занимать до четырех байтов.
Современные приложения чаще используют UTF-8, который поддерживает все символы кодов EUC и многое другое, и, как правило, более переносим с меньшим количеством отклонений и ошибок от поставщиков. Однако EUC по-прежнему очень популярен, особенно EUC-KR для Южной Кореи.
EUC-CN
 | |
| MIME / IANA | GB2312 |
|---|---|
| Псевдоним (а) | csGB2312 |
| Язык (и) | Упрощенный китайский, английский, русский |
| Стандарт | ГБ 2312 (1980) |
| Классификация | Расширенный ASCII, кодирование с переменной шириной, Кодирование CJK, EUC |
| Расширяется | US-ASCII |
| Расширения | 748, ГБК, ГБ 18030, x-mac-chinesesimp |
| Преобразует / кодирует | ГБ 2312 |
| Преемник | ГБК, ГБ 18030 |
EUC-CN[1] это обычная закодированная форма ГБ 2312 стандарт для упрощенные китайские иероглифы. В отличие от японского JIS X 0208 и ISO-2022-JP, ГБ 2312 обычно не используется в 7-битных ISO 2022 версия кода,[а] хотя вариантная форма называется Гц (который разграничивает ГБ 2312 текст с последовательностями ASCII) иногда использовался на USENET.
Символ ASCII представлен в своей обычной кодировке. Персонаж из ГБ 2312 представлен двумя байтами, оба из диапазона 0xA1–0xFE.
Связанные системы кодирования упрощенного китайского
Код 748
Кодировка, относящаяся к EUC-CN, - это код «748», используемый в системе набора текста WITS, разработанной компанией Beijing Founder Technology (в настоящее время устарел ее новой системой набора текста FITS). Код 748 содержит все ГБ 2312, но не ISO 2022–Соответствующий и, следовательно, не настоящий код EUC. (Он использует 8-битный ведущий байт, но различает второй байт с его наиболее значимым набором битов и один с очищенным его наиболее значимым битом, и поэтому он более похож по структуре на Big5 и другие, не соответствующие требованиям ISO 2022 DBCS Системы кодирования.) Часть кода 748, отличная от GB2312, содержит традиционные и гонконгские символы и другие глифы, используемые при наборе газет.
GBK и GB 18030
ГБК является расширением ГБ 2312. Он определяет расширенную форму кодирования EUC-CN, способную представлять больший массив CJK персонажи поступает в основном из Unicode 1.1, включая традиционный китайский символы и символы, используемые только в Японский. Однако это не настоящий код EUC, потому что байты ASCII могут отображаться как байты следа (и С1 байты (не ограничиваясь одиночными сдвигами, могут отображаться как начальные или конечные байты), поскольку требуется большее пространство для кодирования.
Варианты ГБК реализуются Кодовая страница Windows 936 (в Майкрософт Виндоус кодовая страница для упрощенного китайского) и кодовой страницей IBM 1386.
На основе Unicode ГБ 18030 кодировка символов определяет расширение GBK, способное кодировать все Unicode. Однако Unicode закодирован как ГБ 18030 это кодирование с переменной шириной который может использовать до четырех байтов на символ из-за того, что требуется еще большее пространство для кодирования. Являясь расширением GBK, он является расширенным набором EUC-CN, но сам по себе не является настоящим кодом EUC. Будучи кодировкой Unicode, ее репертуар идентичен репертуару других Форматы преобразования Unicode Такие как UTF-8.
Mac OS Китайский упрощенный
Другие варианты EUC-CN, отклоняющиеся от механизма EUC, включают Mac OS Китайский упрощенный сценарий (известный как кодовая страница 10008 или x-mac-chinesesimp).[2] Он использует байты 0x80, 0x81, 0x82, 0xA0, 0xFD, 0xFE и 0xFF для U с умлаутом (ü), два специальных символа метрики шрифта, неразрывное пространство, то знак авторского права (©), знак товарного знака (™) и многоточие (…) соответственно.[1] Это отличается тем, что считается однобайтовым символом по сравнению с первым байтом двухбайтового символа как из EUC (где из них 0xFD и 0xFE определены как ведущие байты), так и из GBK (где из них 0x81, 0x82, 0xFD и 0xFE определены как ведущие байты).
Это использование совпадений 0xA0, 0xFD, 0xFE и 0xFF Вариант Shift_JIS от Apple.
EUC-JP
 | |
| MIME / IANA | EUC-JP |
|---|---|
| Псевдоним (а) | Unixized JIS (UJIS), csEUCPkdFmtЯпонский |
| Язык (и) | Японский, английский, русский |
| Классификация | Расширенный ISO 646, кодирование с переменной шириной, Кодирование CJK, EUC |
| Расширяется | US-ASCII или же ISO 646: JP |
| Преобразует / кодирует | JIS X 0208, JIS X 0212, JIS X 0201 |
| Преемник | EUC-JISx0213 |
| Псевдоним (а) | EUC-JISx0213 |
|---|---|
| Язык (и) | Японский, Айны, английский, русский |
| Стандарт | JIS X 0213 |
| Классификация | Расширенный ASCII, кодирование с переменной шириной, Кодирование CJK, EUC |
| Расширяется | US-ASCII |
| Преобразует / кодирует | JIS X 0213, JIS X 0201 (Кана) |
| Предшествует | EUC-JP |
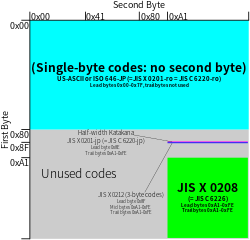
EUC-JP это кодирование с переменной шириной используется для представления элементов трех Японские стандарты набора символов, а именно JIS X 0208, JIS X 0212, и JIS X 0201. Другие имена для этой кодировки включают Unixized JIS (или же UJIS) и AT&T JIS.[3] 0,1% всех веб-страниц используют EUC-JP с августа 2018 года,[4] в то время как 3,2% японских веб-сайтов используют эту кодировку (реже, чем Shift JIS, или же UTF-8 ). Это называется Кодовая страница 954 компании IBM.[5][6] У Microsoft есть два номера кодовой страницы для этой кодировки (51932 и 20932).
Эта схема кодирования позволяет легко смешивать 7-битный ASCII и 8-битный японский язык без необходимости использования escape-символов, используемых ISO-2022-JP, который основан на тех же стандартах набора символов, и без байтов ASCII, появляющихся как байты следа (в отличие от Shift JIS ).
Связанная и частично совместимая кодировка, называемая EUC-JISx0213 или же EUC-JIS-2004, кодирует JIS X 0201 и JIS X 0213[7] (аналогично Shift_JISx0213, его аналог на основе Shift_JIS).
По сравнению с EUC-CN или EUC-KR, EUC-JP не получил такого широкого распространения на ПК и системах Macintosh в Японии, которые использовали Shift JIS или его расширения (Кодовая страница Windows 932 на Майкрософт Виндоус, и MacЯпонский на классическая Mac OS ), хотя он стал широко использоваться Unix или Unix-подобный операционные системы (кроме HP-UX ). Поэтому, используют ли японские веб-сайты EUC-JP или Shift_JIS, часто зависит от того, какую ОС использует автор.
Расширения поставщика для EUC-JP обычно назначались в рамках отдельных кодовых наборов,[8] в отличие от использования недопустимых последовательностей EUC (как в популярных расширениях EUC-CN и EUC-KR).
Символы кодируются следующим образом:
- Как EUC /ISO 2022 совместимая кодировка, C0 управляющие символы, пробел и DEL представлены как в ASCII.
- Графический персонаж из ASCII (кодовый набор 0) представлен как его обычное однобайтовое представление в диапазоне 0x21 - 0x7E. Хотя некоторые варианты EUC-JP кодируют нижняя половина из JIS X 0201 здесь большинство кодирует ASCII,[9] включая стандарт кодирования W3C / WHATWG, используемый HTML5,[10] как и EUC-JIS-2004.[7] Хотя это означает, что 0x5C обычно отображается в Unicode как U + 005C REVERSE SOLIDUS (ASCII обратная косая черта ), U + 005C может отображаться как Знак иены некоторыми шрифтами для японского языка, например в Microsoft Windows для совместимости с нижней половиной JIS X 0201.[11][12]
- Символ из JIS X 0208 (кодовый набор 1) представлен двумя байтами, оба в диапазоне 0xA1 - 0xFE. Это отличается от представления ISO-2022-JP наличием старшего бита. Этот кодовый набор может также содержать расширения поставщиков в некоторых вариантах EUC-JP. В EUC-JIS-2004 первый самолет JIS X 0213 кодируется здесь, что, по сути, является расширением стандартных JIS X 0208.[7]
- Персонаж из верхняя половина из JIS X 0201 (кана половинной ширины, кодовый набор 2) представлен двумя байтами, первый из которых - 0x8E, второй - обычный JIS X 0201 представление в диапазоне 0xA1 - 0xDF. Этот набор может содержать Расширения поставщиков IBM в некоторых вариантах.
- Символ из JIS X 0212 (кодовый набор 3) представлен в EUC-JP тремя байтами, первый из которых равен 0x8F, а следующие два находятся в диапазоне 0xA1–0xFE, то есть с установленным старшим битом. Помимо стандартных JIS X 0212кодовый набор 3 некоторых вариантов EUC-JP может также содержать расширения в строках 83 и 84 для представления символов из расширений IBM Shift JIS, в которых отсутствуют стандартные сопоставления JIS X 0212, которые могут быть закодированы в любом из двух макетов, один из которых определяется самим IBM и один, определенный OSF.[8][13] В EUC-JIS-2004 второй самолет JIS X 0213 здесь закодировано,[7] который не конфликтует с выделенными строками в стандартных JIS X 0212.[14] Некоторые реализации EUC-JIS-2004, например, используемая Python, разрешите оба JIS X 0212 и JIS X 0213 самолет 2 персонажа в этом наборе.[14]
EUC-KR
 Структура кода EUC-KR | |
| MIME / IANA | EUC-KR |
|---|---|
| Псевдоним (а) | Вансунг, IBM-970 |
| Язык (и) | Корейский, английский, русский |
| Стандарт | KS X 2901 (KS C 5861) |
| Классификация | Расширенный ISO 646, кодирование с переменной шириной, Кодирование CJK, EUC |
| Расширяется | US-ASCII или же ISO 646: KR |
| Расширения | Mac OS корейский, IBM-949, Единый код хангыль (Windows-949) |
| Преобразует / кодирует | KS X 1001 |
| Преемник | Единый код хангыль (веб-стандарты) |
EUC-KR это кодирование с переменной шириной для представления корейского текста с использованием двух наборов кодированных символов, KS X 1001 (ранее KS C 5601)[15][16] и либо ISO 646: KR (KS X 1003, ранее KS C 5636) или же US-ASCII, в зависимости от варианта. KS X 2901 (ранее KS C 5861) определяет кодировку и RFC 1557 назвал его EUC-KR.
Символ, взятый из KS X 1001 (G1, кодовый набор 1), кодируется как два байта в GR (0xA1–0xFE) и символ из KS X 1003 или US-ASCII (G0, кодовый набор 0) занимает один байт в GL (0x21–0x7E).
При использовании с ASCII он называется Кодовая страница 970 компании IBM.[17][18][19] Он известен как Кодовая страница 51949 от Microsoft.[20] Обычно его называют Wansung (Корейский: 완성, романизированный: Wanseong, горит заранее составленный[21]') в Республика Корея.
По состоянию на июль 2020 г.[Обновить], 0,1% всех веб-страниц в мире используют EUC-KR,[4] что вводит в заблуждение, поскольку 15,6% веб-страниц Южной Кореи используют (только страна, для которой предназначена кодировка),[22] что делает его самым популярным не-UTF-8 / Кодировка Unicode для языка / веб-домена, в то время как только 8,4% веб-страниц используют корейский язык (что делает UTF-8 менее популярным в Южной Корее, чем во всех (по-видимому) странах мира).[23] Включая расширения, это наиболее широко используемая устаревшая кодировка символов в Корее на всех трех основных платформах (macOS, другие Unix-подобные ОС и Windows), но его использование очень медленно переходило на UTF-8 поскольку он набирает популярность, особенно в Linux и macOS.
Как и в большинстве других кодировок, UTF-8 теперь предпочтительнее для нового использования, решая проблемы с согласованностью между платформами и поставщиками.
Связанные корейские системы кодирования
Единый код хангыль
Распространенным расширением EUC-KR является Единый код хангыль (통합형 한글 코드, Тонхабхён Хангыль Кодеу,[24] или же 통합 완성형, Тонгаб Вансонхён), которая является корейской кодовой страницей по умолчанию в Microsoft Windows (кодовая страница 949, номер 1363 от IBM). Кодовая страница IBM 949 это другое, не связанное с этим расширение EUC-KR.
Унифицированный код хангыль расширяет EUC-KR за счет использования кодов, которые не соответствуют структуре EUC, для включения дополнительных слоговых блоков, завершая охват составных слоговых блоков, доступных в Йохаб и Unicode. В W3C /WHATWG Стандарт кодирования, используемый HTML5 включает расширения Унифицированного кода хангыль в свое определение EUC-KR.[25]
Mac OS корейский (HangulTalk)
Другие расширения, совместимые с EUC-KR, включают корейскую кодировку Mac OS, используемую классическая Mac OS.
EUC-TW
EUC-TW это кодирование с переменной шириной который поддерживает US-ASCII и 16 самолетов CNS 11643, каждая из которых имеет размер 94x94. Это редко используемая кодировка для традиционные китайские иероглифы как используется в Тайвань. Варианты Big5 гораздо более распространены, чем EUC-TW, хотя Big5 кодирует только первые две плоскости CNS 11643 Ханзи, пока UTF-8 становится все более распространенным.
- Как EUC /ISO 2022 кодирование, C0 управляющие символы, Пробел ASCII и DEL кодируются как в ASCII.
- Графический символ из US-ASCII (G0, кодовый набор 0) кодируется в GL как его обычное однобайтовое представление (0x21–0x7E).
- Символ из плоскости 1 CNS 11643 (кодовый набор 1) кодируется как два байта в GR (0xA1–0xFE).
- Символ в плоскости с 1 по 16 CNS 11643 (кодовый набор 2) кодируется четырьмя байтами:
- Первый байт всегда 0x8E (одиночный сдвиг 2).
- Второй байт (0xA1–0xB0) указывает плоскость, номер которой получается вычитанием 0xA0 из этого байта.
- Третий и четвертый байты находятся в GR (0xA1–0xFE).
Обратите внимание, что плоскость 1 CNS 11643 кодируется дважды как кодовый набор 1 и часть кодового набора 2.
Упакованная форма по сравнению с формой фиксированной длины
Кодировки, описанные выше (с использованием байтов в 0x21–0x7E для кодового набора 0, байтов в 0xA1–0xFE для кодового набора 1, 0x8E с последующими байтами в 0xA1–0xFE для кодового набора 2 и 0x8F, за которыми следуют байты в 0xA1–0xFE для кодового набора 3) находятся в переменная ширина форма, именуемая Упакованный формат EUC. Эта форма обычно обозначается как EUC.[3]
Внутренняя обработка может использовать альтернативную форму фиксированной длины, называемую Полный двухбайтовый формат EUC. Это означает:[3]
- Кодовый набор 0 как два байта в диапазоне 0x21–0x7E (за исключением того, что первый может быть 0x00).
- Кодовый набор 1 как два байта в диапазоне 0xA0–0xFF (за исключением того, что первый может быть 0x80).
- Кодовый набор 2 в виде байта в диапазоне 0x20–0x7E (или 0x00), за которым следует байт в диапазоне 0xA0–0xFF.
- Кодовый набор 3 в виде байта в диапазоне 0xA0–0xFF (или 0x80), за которым следует байт в диапазоне 0x21–0x7E.
Начальные байты 0x00 и 0x80 используются в случаях, когда кодовый набор использует только один байт. Существует также четырехбайтовый формат фиксированной длины.[3] Эти формы фиксированной длины подходят для внутренней обработки и обычно не встречаются при обмене.
EUC-JP зарегистрирован IANA в обоих форматах: в упакованном формате как «EUC-JP» или «csEUCPkdFmtJapanese» и в формате фиксированной ширины как «csEUCFixWidJapanese».[26] Только упакованный формат включен в WHATWG Стандарт кодирования, используемый HTML5.[27]
Смотрите также
Примечания
- ^ Поддержка 7-битных версий кода ISO 2022 ГБ 2312 включают ISO-2022-CN (с кодами смены) и ISO-2022-JP-2 (без кодов сдвига), оба из которых также поддерживают другие наборы, отличные от ASCII.
Рекомендации
- ^ а б «Карта (внешняя версия) из упрощенной китайской кодировки Mac OS в Unicode 3.0 и выше». Apple, Inc.
- ^ "Свойство Encoding.WindowsCodePage - .NET Framework (текущая версия)". MSDN. Microsoft.
- ^ а б c d Лунде, Кен (2008). Обработка информации CJKV: вычисления на китайском, японском, корейском и вьетнамском языках. О'Рейли. С. 242–244. ISBN 9780596800925.
- ^ а б «Исторические тенденции использования кодировок символов для веб-сайтов». W3Techs.
- ^ «Информационный документ CCSID 954». Архивировано из оригинал on 2016-03-27.
- ^ Международные компоненты для Unicode (ICU), ibm-954_P101-2007.ucm, 2002-12-03
- ^ а б c d «Таблицы сопоставления кодов JIS X 0213». x0213.org.
- ^ а б "4.2 Обзор процесса преобразования правил преобразования кодового набора между eucJP-open и UCS". Проблемы и решения для Unicode и символов, определенных пользователем / поставщиком. Открытая группа в Японии. Архивировано из оригинал на 1999-02-03. Получено 2019-08-14.
- ^ «Неопределенность при преобразовании японского EUC в Unicode (ненормативный)». XML японский профиль. W3C.
- ^ «Декодер EUC-JP». Стандарт кодирования. WHATWG. «Если байт является байтом ASCII, вернуть кодовую точку, значение которой - байт».
- ^ «3.1.1 Подробности проблем». Проблемы и решения для Unicode и символов, определенных пользователем / поставщиком. Открытая группа в Японии. Архивировано из оригинал на 1999-02-03. Получено 2019-08-14.
- ^ Каплан, Майкл С. (17 сентября 2005 г.). "Когда обратная косая черта не является обратной?".
- ^ Лунде, Кен (13 января 2009 г.). «Приложение J: Наборы японских символов» (PDF). CJKV Обработка информации (2-е изд.). ISBN 978-0-596-51447-1.
- ^ а б Чанг, Хешик. "Readme для CJKCodecs". cPython. Фонд программного обеспечения Python.
- ^ "KS X 1001: 1992" (PDF).
- ^ "KS C 5601: 1987" (PDF). 1988-10-01.
- ^ «CCSID 970». IBM Глобализация. IBM. Архивировано из оригинал на 2014-12-01.
- ^ "ibm-970_P110_P110-2006_U2 (псевдоним euc-kr)". Converter Explorer - Демонстрация ICU. Международные компоненты для Unicode.
- ^ Международные компоненты для Unicode (ICU), ibm-970_P110_P110-2006_U2.ucm, 2002-12-03
- ^ «Идентификаторы кодовой страницы». Центр разработки для Windows. Microsoft.
- ^ Лунде, Кен (2009). «Глава 3: Стандарты набора символов». CJKV Обработка информации. п. 146. ISBN 978-0596514471.
- ^ «Распределение кодировок символов среди веб-сайтов, использующих .kr». w3techs.com. Получено 2020-07-03.
- ^ «Распределение кодировок символов среди веб-сайтов, использующих корейский язык». w3techs.com. Получено 2020-07-03.
- ^ "한글 코드 에 대하여" (на корейском). W3C. Архивировано из оригинал на 2013-05-24. Получено 2019-01-07.
- ^ «5. Индексы (§ индекс EUC-KR)», Стандарт кодирования, WHATWG
- ^ «Наборы символов». IANA.
- ^ «4.2. Имена и ярлыки». Стандарт кодирования. WHATWG.
внешняя ссылка
- Таблица кодов EUC-JP (без ASCII и половинной части)
- Идентификаторы кодовой страницы
- GB18030-2000 - Новый китайский национальный стандарт
- Новое поколение программного обеспечения допечатной подготовки в Китае - упоминает код 748
- Описание кода EUC-TW (на китайском)
- Страница руководства EUC-JISX0213 в модуле Perl Encode
- Международный регистр наборов кодированных символов для использования с escape-последовательностью - раздел 2.4 (стр. 14f.) С наборами кодированных символов Китая, Японии, Южной Кореи, Северной Кореи и Тайваня (ISO / IEC)
- Стандарты набора символов китайского, японского и корейского языков и системы кодирования